
When To Use Immutable Data Structures
Suppose you are asked this question during a technical interview:
When do you use immutable (functional) data structures and when do you use mutable data structure?
To answer this question, let’s go over some basics first.
Mutable vs. Immutable Data structure
To illustrate the differences between mutable and immutable data structure, we are going to implement the queue using an array.
The definition of a queue:
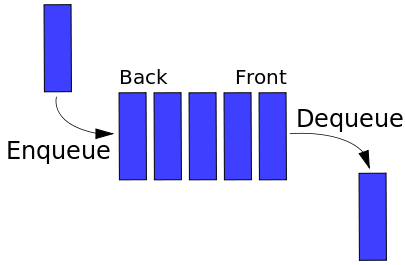
Note, I’m using an array to represent the Queue for simplicity. That’s not the correct way. Queue has the property of O(1) enqueue and dequeue operations. Using an array to represent a Queue results in O(N) enqueue and dequeue operations. A correct implementation of a queue uses a DoublyNode and two pointers for head and tail of the Queue.
Here’s an implementation of the Queue as an mutable data structure.
function QueueMutable() {
let arr = [] // private variable
this.enqueue = val => {
arr.push(val)
return this
}
this.dequeue = () => {
let head = arr.shift()
return [head, this]
}
this.isEmpty = () => arr.length === 0
this.getData = () => arr
}
Here’s an implementation of the Queue as a immutable data structure.
function QueueImmutable(dataIn = []) { // data is an optional parameter
let data = dataIn // private variable
this.enqueue = item => {
let newData = data.concat([item]) // concat returns a new arr
return new QueueImmutable(newData)
}
this.dequeue = () => {
let [head, ...rest] = data
return [head, new QueueImmutable(rest)]
}
this.getData = () => data
this.isEmpty = () => data.length === 0
}
One key difference you may have noticed is that the immutable Queue does not mutate the original queue. enqueue and dequeue functions returns a new queue data structure.
Try out these Queue implementations in repl.
Pros and Cons
Consider this example:
let qIm = new QueueImmutable()
qIm.enqueue(1)
console.log(qIm.getData()) //> A
qIm.enqueue(2)
qIm.enqueue(3)
console.log(qIm.getData()) //> B
let qM = new QueueMutable()
qM.enqueue(1)
console.log(qIm.getData()) //> C
qM.enqueue(2)
qM.enqueue(3)
console.log(qIm.getData()) //> D
qIm.getData() always returns [] at lines A and B because qIm hasn’t changed. On the other hand, each time we call qM.getData(), we get different results: The call on line C returns [1] and the call on line D returns [1,2,3].
Why is it an advantage to return the same results for the same input? Better predicability, maintability, and less buggy code.
There’s a concept in functional programming called referential transparency forces the invariant that everything a function does is represented by the value that it returns.
Immutable data structures provides referential transparency which makes it easier to reason about our program locally.
Another way to think about it is that every time we execute a pure (referentially transparent) function with the same input, we get the same output. Pure functions do not depend on context (e.g., when you execute function in your overall program) and may be reasoned about locally. On the other hand, functions which are not referentially transparent produce results which are context-dependent, require more global reasoning, are harder to refactor, and are more likely to introduce nasty bugs due to side effects.
An obvious disadvantage with using an immutable data structure is you are creating a new data structure every time you want to make a change.
At first glance, both Queue implementations seem to have identical behavior and can be used to construct a queue with almost identical syntax using chaining:
let qM = new QueueMutable()
qM.enqueue(1).enqueue(2).enqueue(3).dequeue()[1]
console.log(qM.getData()) //> [2,3]
let qIM = new QueueImmutable()
qIm = qIm.enqueue(1).enqueue(2).enqueue(3).dequeue()[1]
console.log(qIm.getData()) //> [2,3]
Notice we don’t need to reassign qM to point to a new data structure since the original data structure is modified in place via enqueue and dequeue.
However, for the immutable Queue, a new Queue is created each time we call enqueue and dequeue, so that’s four new Queues total to support the four Queue operations. Also we needed to update the qIm to point to the final Queue containing 2 and 3 which was created by the dequeue function.
When to use immutable data structure
In concurrent programs, functional programming and immutable data structures are used to ensure correctness when multiple parts of the program use shared resource. The shared resource is encoded in an immutable data structure.
Modern client side applications often have multiple components (e.g., parts of the DOM or screens of a single page application) access and making changes to the same shared state. React and redux provides a powerful framework for building rich client side applications which rely on heavily on functional programming techniques. For instance, redux provides an an abstraction for managing shared data by leveraging immutable data structure and a collection of functions called reducers and actions to provide a “single source of truth” to multiple React components.
When to use mutable data structure
When concurrency and resource sharing are not involved and you are concerned with making your program run as fast as possible, you are better off using mutable data structures. Using an immutable data structure is expensive because it’s creating a new modified version of a data structure every time you want to make a change.
In game programming, memory allocation is usually the slowest thing (resource pools are popular in game programming). In games you not only want each frame to process quickly but also for speed to be consistent. The usual symptom of a garbage collector bottleneck is that the game intermittently freezes but runs normally in between. In that case, you don’t want to continuously allocate memory for the new data structure; rather you want to update the existing data structure in place.
