
Building an Isomorphic Webapp
I’ve always lived by the “Separation of Concern” principle when it comes to software design. Recently, I’ve came to love a new design pattern for web apps called the isomorphic web app that sacrifices some of the simplicity of a SPA with a backend API for a significant boost in performance.
Overview
At a high level, isomorphic web app is a design pattern that renders the same web page from both the server side and the client side. In the isomorphic web app starter project built using React.js, Node.js, we take advantage of the fact that both the server and client are built in JavaScript. This enables us to use the same code for rendering the web pages for both the server and client rendering. The complicated part is to build a server wrapper and a client wrapper for the shared code.
Motivation
For web development, the Single Page Application (SPA) that talks to a server API was once the gold standard as it provides the most clear division of responsibilities between the server app and client app. The server serves the data (usually JSON) to the client app to render the web page in the browser. What could go wrong with this approach? Performance.
A SPA is a client side (browser rendered) application that bootstraps the entire website after initial load. This means when you visit example.com using your browser, example.com’s server sends a HTML template and some javascript for your browser to execute the code that renders the actual content of the webpage. Because the tight coupling of the code that creates the DOM and the DOM, SPAs can handle complex DOM manipulation.
We are all familiar with the features of a SPA: quick response to user input, highly interactive webpages (think google docs), and ability to use it offline once the page loads. Most importantly for a startup founder such as myself who’s trying to quickly create a prototype of a website with some dummy data, a SPA lets you build a website independently from a server application. In many cases, you can get away with not building a server application at all if you used a sophisticated front end library like React, Amazon S3 for hosting, and data you store in a CSV file. That’s exactly what I did for LooseLeaf.
This separation of concerns improves productivity initially when you are prototyping a MVP for your website, but there’s a point of diminishing returns for a website deployed as a SPA that talks to a server with an API for data. The main disadvantages of this approach are:
Long load time (bad UX)
because the website is bootstrapped, it takes some time for the page content to display itself after the initial load. Initial load occurs when you type the example.com into your browser and press enter. Whatever the browser gets back from the initial load is whatever the server sends.
If the server sends a blank HTML template and javascript to render stuff into that template, then the user will see a blank page and a maybe a page loading animation. How long the user has to wait until something is displayed scales with the complexity of the webpage and how fast their internet service is so on a mobile device, pages tend to load much slower.
Bad SEO (bad for business)
Search engines and social sharing are two of the most important means of acquiring new users.
Think of search engine optimization (SEO) as ways to get Google to rank your webpage higher on the list to relevant query searches. For Google to rank your webpage content, it needs to know what content’s in your webpage. Google deploys an army of crawlers, which are just programs that make requests to webpages, look at the response, scrap content off the HTML, and look at how to rank that webpage amongst other webpages on the internet based on relevance. These crawlers don’t generally run JavaScript or wait around for a long time for the page to render itself. If your webpage gives the crawler blank pages on initial load, then Google will not know what your page is about to accurately place your webpage high up on the hits list when a relevant search query is entered on google.com.
The same thing happens with social media sites like Facebook and Twitter sharing who have their own army of crawlers to render a preview of the page based on meta tags in the header of HTML. The header is rendered on the server side and don’t change when the content changes based on dynamic loading when the webpage is bootstrapped in the browser. This means if you have a website that sells books and a SPA that uses the same template HTML to render different pages for different books, then when you share a link to the page for a particular book on Facebook, the preview will display a generic preview about your website which says something like it’s a place which sells thousands of titles, but will not display any unique information for the particular book. This article did a good job laying out the limitation of a SPA in its ability to generate unique header for social sharing and how to use server rendering to solve that.
What about Pure Server Rendering Solutions?
If you are reading this, that means I’ve convinced you that a simple SPA is not the way to go. A pure server side application is not the way to go either because from a development standpoint, we want to be able to build our client application and server application separately. From a user experience standpoint, once a SPA is fully loaded, user experience may greatly exceed that of a server-rendered webpage. Also I don’t want the entire page to reload every time I click a button.
So the shortcoming of a pure SPA is in the initial load. The shortcoming of the pure server rendering solution is with what happens after the initial load. What can we do to get the best of both worlds? 🤔
Isomorphic Web App Starter Project
I like to think of an isomorphic web app as SPA 2.0. It’s SPA with server side rendering. An isomorphic web app gives you the best of both server side rendering and single page application (SPA). There have been many articles written about the benefits of an isomorphic web app, like this, this, this, and this. There’s a book being written about it. However, not that many tutorials, guides or starter projects to help you get started building an isomorphic app.
Through reading dozens of articles, tutorials, books, and undergoing trial and error, I managed to set up an isomorphic web app that uses the latest stack in the Node and React ecosystem. This include React Router v4, Webpack 4, and Babel.
The isomorphic web app starter project I created takes advantage of the fact that JavaScript is used to build both the client application and the server application. This promotes code reusability as we can use the same code to render the SPA as well as the HTML for the server to send for the initial load.
All the code is contained in this repository: https://github.com/xiaoyunyang/isomorphic-router-demo
To get the code up and running on localhost:3000, simply do:
$ git clone https://github.com/xiaoyunyang/isomorphic-router-demo.git
$ cd isomorphic-router-demo
$ npm install
$ npm start
Here’s a preview for what it looks like:
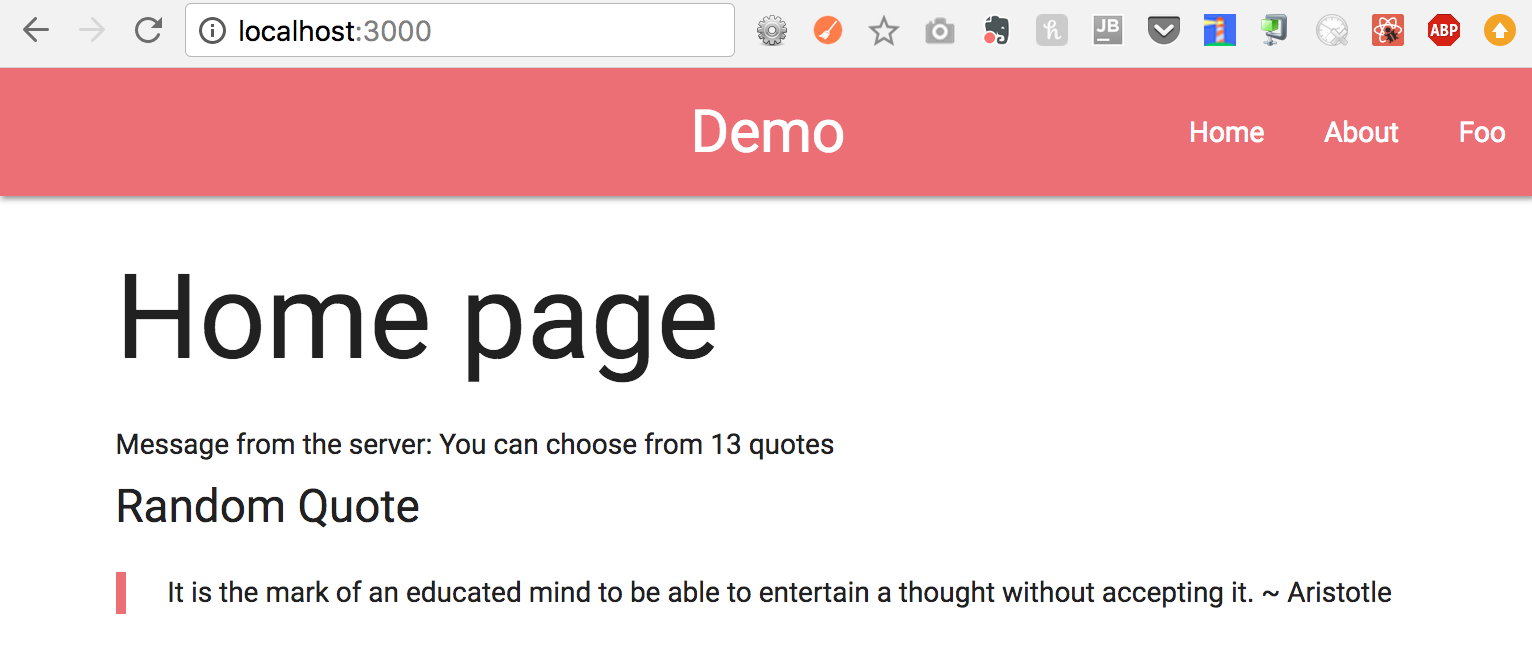 Home Page
Home Page
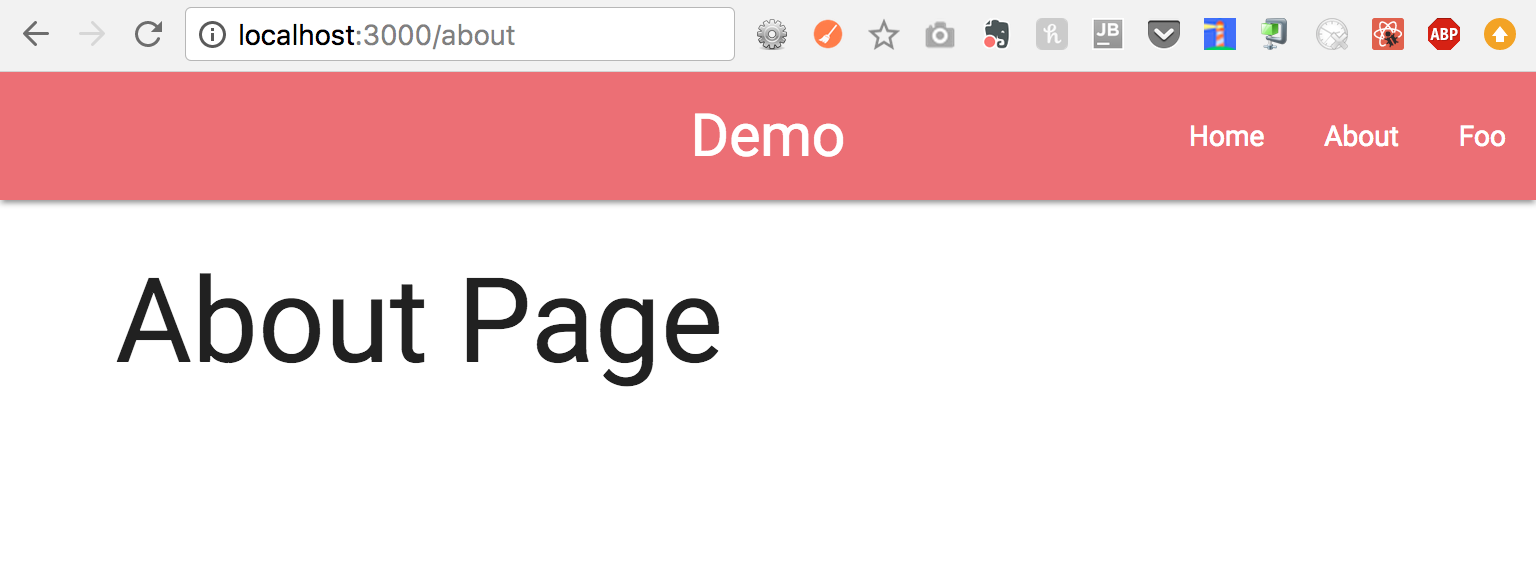 About Page
About Page
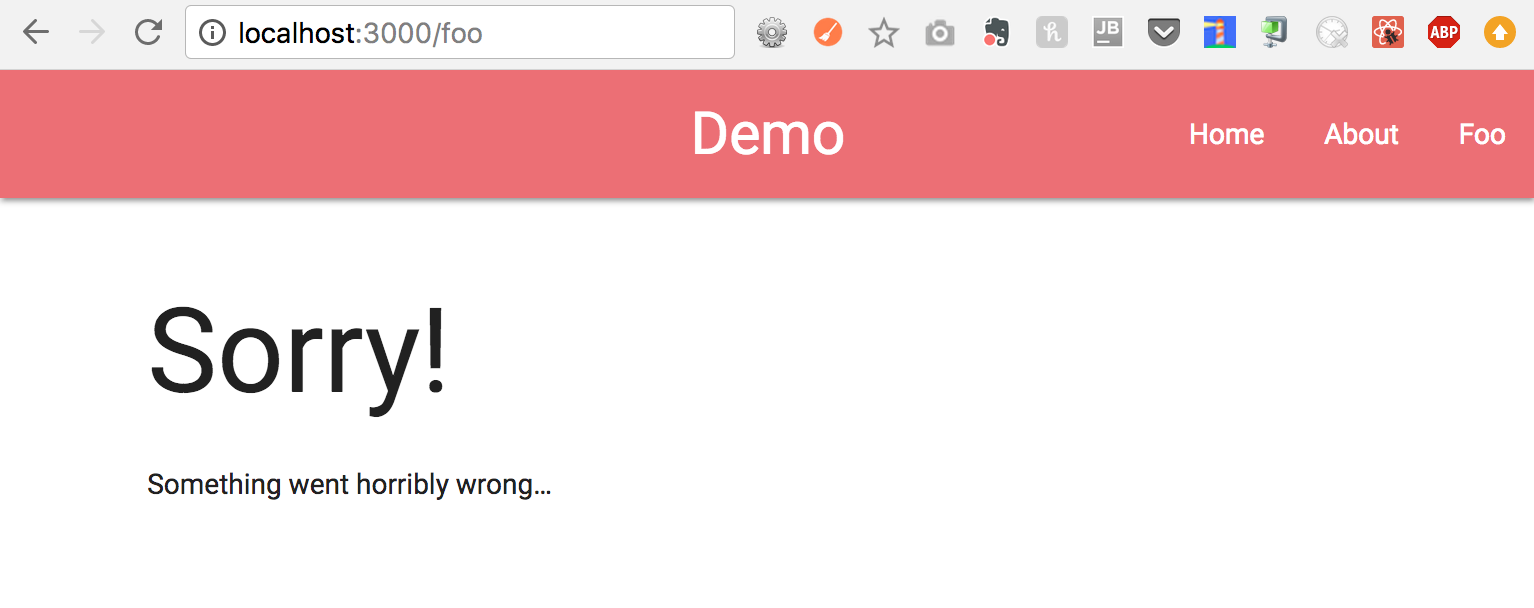 Not Found Page
Not Found Page
Bottomline
Client side rendering and server side rendering complement each other. We can build an isomorphic web app that enhances the capability of a server rendered page with a SPA. As articulated in Lullabot’s article, there’s a considerable learning curve when building an isomorphic application for the first time, but like anything with a steep learning curve, there’s nothing you can’t figure out with a bit of googling, experimentation, and leveraging tutorials and sample projects.
